Can you really interrupt an LLM?
You never see that in the demos... why?
With the recent release of Voice Mode for Claude, it seems like Voice AI is a solved problem. Now that LLMs can speak natively, there's apparently no more need for any of the complex voice pipelines that used to be necessary last year: no need to do voice activity detection, no need to pipe data from the speech-to-text model to the LLM and then back to the text-to-speech engine at blazing speed in order to achieve a natural conversation flow. Modern LLMs can laugh and sing: what else could we need?
It turns out, a lot is still missing. Here is an example:
Is this an issue with Claude? Have a look at Gemini:
or even at the venerable GPT-4o, the most mature Voice AI out there:
What's going on?
This simple exercise highlights two core issues that are often overlooked when developing Voice AI agents. Let's see them.
Problem #1: LLMs don't perceive time
As algorithms trained to predict the most likely next word, LLMs don't have any concept of time. When dealing with text, this issue is not visible; however as soon as we cross over the domain of voice, their lack of understanding of time becomes a much bigger problem. LLMs still perceive the conversation as a series of tokens, with no concept of speed, pauses, or anything of that sort. They are often trained to control cadence, tone, to imitate pauses and adjust their talking speed, but they don't perceive these features as we do: they are just additional properties of the output tokens.
This means that an LLM will have a very hard time understanding requests that involve altering the timing of the response unless there is additional, external tooling to help them. "Please wait three second before replying", for example, is a meaningless query to an LLM that doesn't have a timer tool of some sort.
For example, here is what GPT-4o (the LLM that handles time best) can do when asked to wait for a few seconds:
Problem #2: Interruptions are not a native capability
Most Voice AIs out there feature the possibility to interrupt them. However, not having any innate concept of time, the ability to interrupt the model has to be implemented on the application end: and this is where it usually goes wrong.
Voice LLMs are very fast: they generate the response in a fraction of the time needed to play it out. When you prompt an LLM, the model will start generate audio tokens and streaming them, but by the time the first one reaches the user, in most cases the majority of the response (if not the entirety of it) has already been generated and is queued in the audio buffer, waiting to be played.
When a user interrupts the LLM, the app normally stops the playback as soon as possible and empties the audio buffer, regardless of its content.
However, unless the app notifies the LLM of this action, the LLM has no way to know that only part of the response was played to the user. This is why most models believe they finished their countdown when in practice they were interrupted earlier.
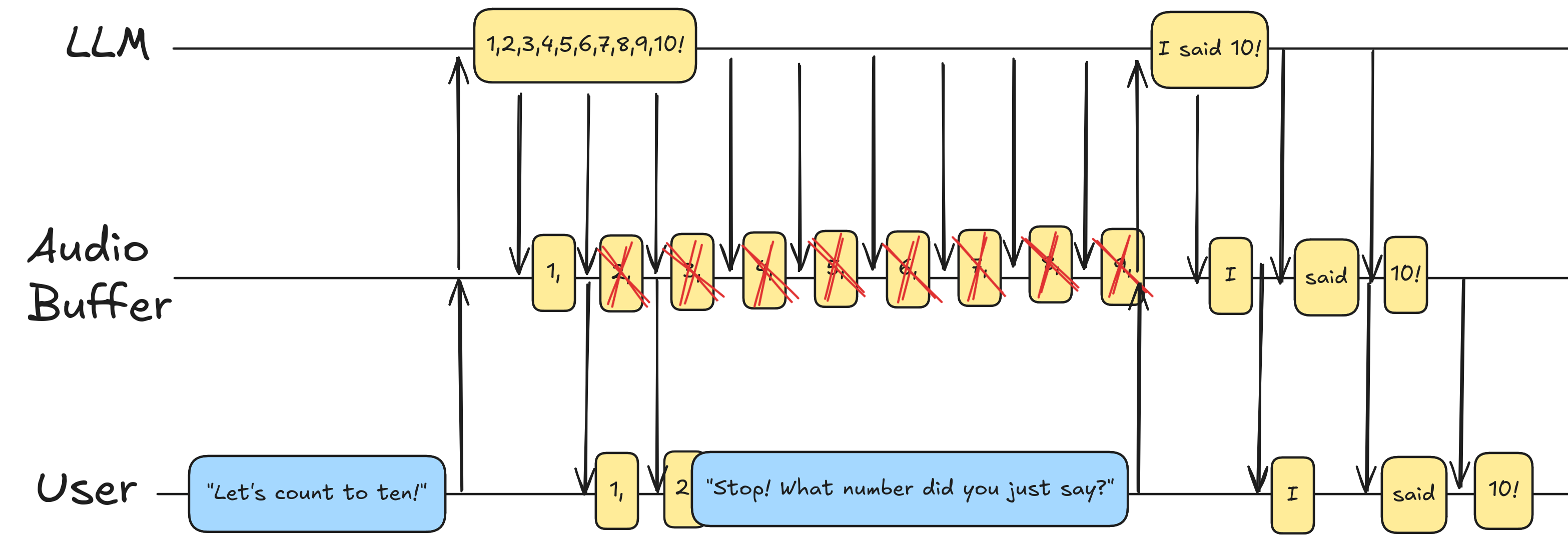
Can it be solved?
If you paid close attention you may have noticed that GPT-4o, while it still stops at the wrong number, it does not believe it completed the countdown, but it understood that the counting was interrupted at some point before the end.
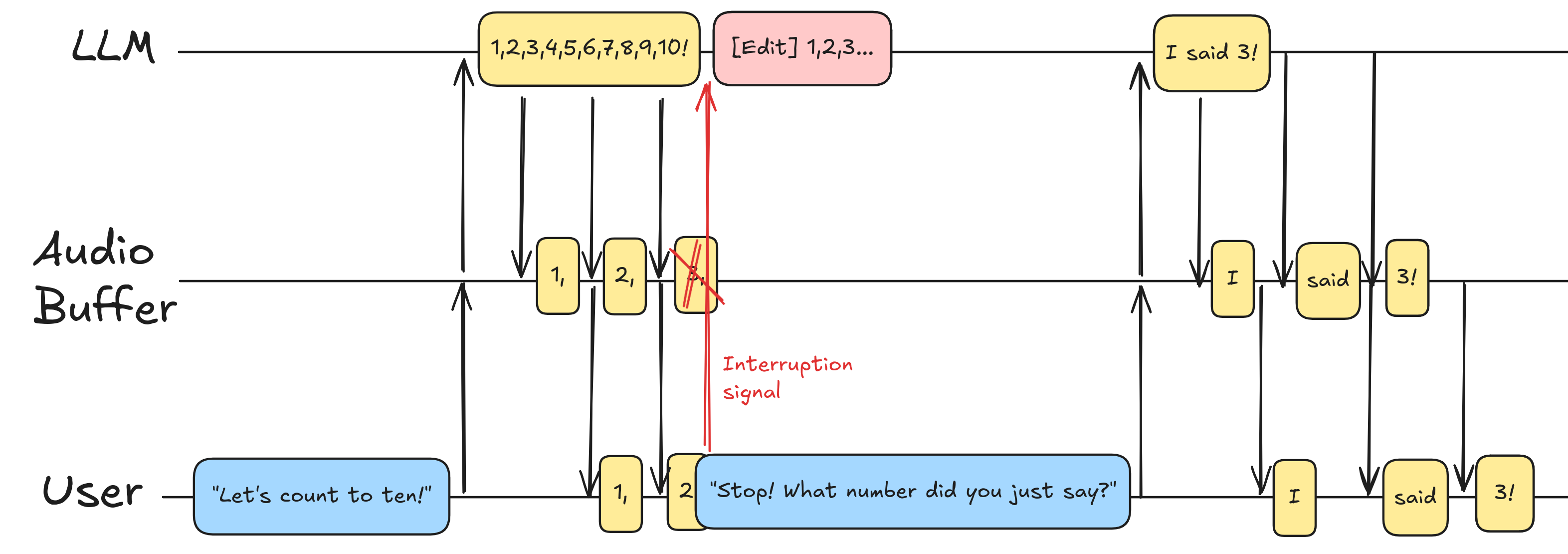
This is possible because OpenAI's Realtime API provides the possibility to tell the model at which point it was interrupted. In the Realtime API documentation you can find this feature implemented with the event conversation.item.truncate (see the docs):
{
"event_id": "event_678",
"type": "conversation.item.truncate",
"item_id": "msg_002",
"content_index": 0,
"audio_end_ms": 1500
}
In this event, the audio_end_ms is what signals the model that the audio was interrupted at a certain time, before its natural end. This event in turn also trims the transcript to make the LLM know what the user heard and was was never played out. Precision however is not trivial to accomplish, because it's very easy for the application to register the interruption later than when it actually occurred and, like in the case of the ChatGPT app, convince the LLM that the interruption happened in the wrong point.
In the case of Gemini, there is a "Handling Interruptions" section in its Live API documentation. However the feature seems incomplete, as they state:
Users can interrupt the model's output at any time. When Voice activity detection (VAD) detects an interruption, the ongoing generation is canceled and discarded. Only the information already sent to the client is retained in the session history.
As we've seen, this is not sufficient to handle interruptions correctly. It's likely that this issue is not currently fixable.
In the case of Claude we don't know yet if that's an inherent limitation or a bug in the app, because at the time of writing there is no Live/Realtime API available for Claude.
Wrapping up
Voice Mode for LLMs is a huge step forward for voice AI, but it's not a silver bullet. LLMs are first and foremost text prediction algorithms, and even when adapted to work with voice, some of their limitations persists. In order to have complete control, building a full pipeline for voice may still be your best bet if you have the infrastructure to achieve a low enough latency; otherwise, always make sure to test the behavior of your LLMs in these corner cases and stick to more well-tested models (in this case, OpenAI's) for better handling of time.