Why using a reranker?
And is the added latency worth it? Let's understand what they do and how can they improve the quality of your RAG pipelines so drastically.
This is episode 1 of a series of shorter blog posts answering questions I received during the course of my work and reflect common misconceptions and doubts about various generative AI technologies. You can find the whole series here: Practical Questions.
Retrieval-Augmented Generation (RAG) systems are essential to connect large language models with external knowledge sources. While in theory the retrieval step is enough to gather documents that are relevant to the user's request, it's often recommended to add an additional ranking step, the reranking, to further filter the results.
But why do we need rerankers? Isn’t semantic search good enough? The answer lies in understanding the limitations of traditional embedding-based retrieval.
Bi-encoders vs Cross-encoders
At the heart of modern, scalable semantic search systems lies the bi-encoder model. This architecture creates independent vector representations for the query and the document; relevance is then computed through a similarity measure like the dot product or cosine similarity between those vectors.
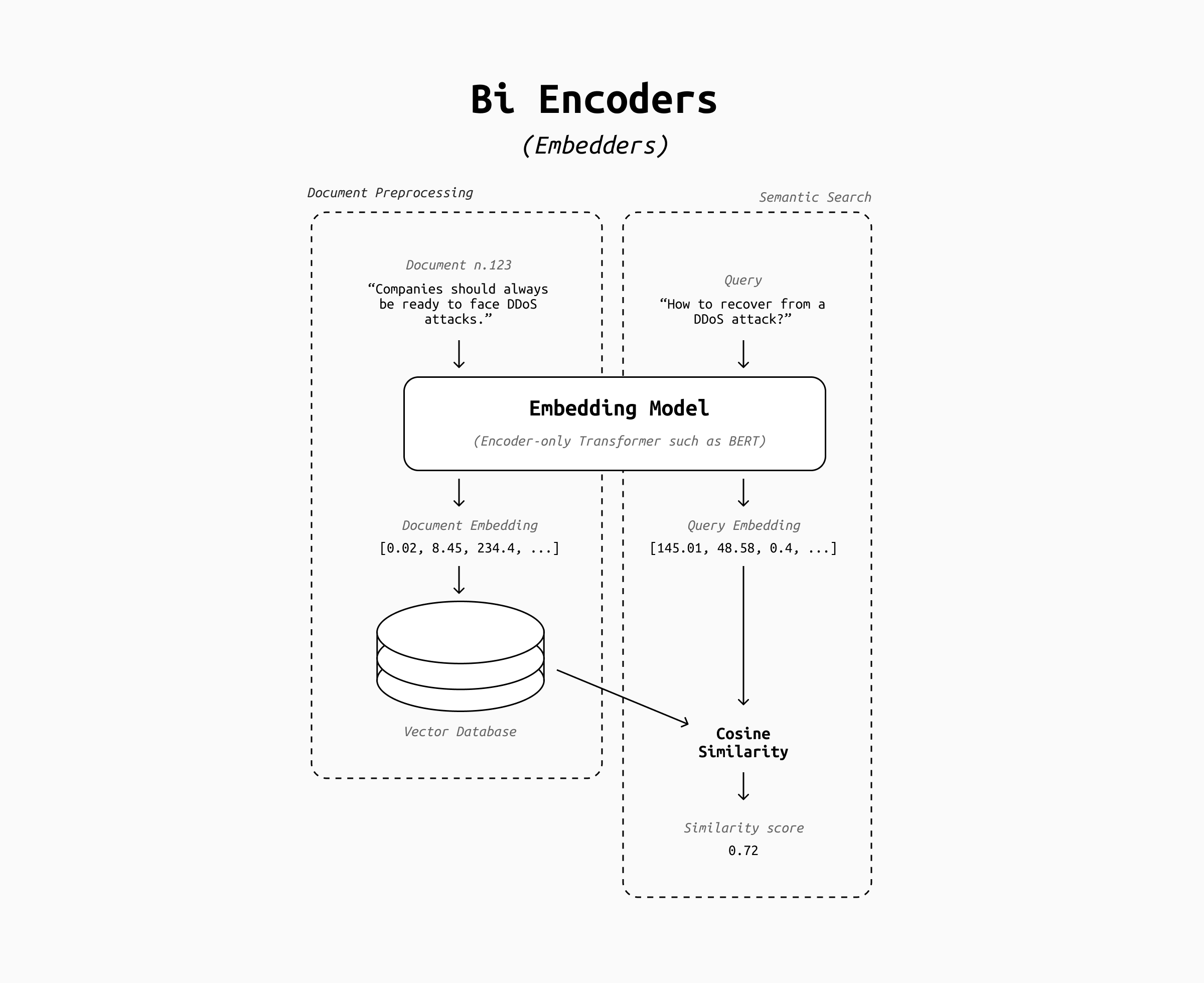
This design scales well: You can precompute document embeddings, store them in your vector DB, and compare any incoming query against millions of documents very efficiently. However, this convenience comes at a cost: the system never truly reads the document in the context of the query. There’s no token-level interaction between the query and document embedding to judge whether the document actually answers the question or it simply happen to be talking about the same topic, and therefore semantically similar.
For example, the query "How to protect my application from DDOS attacks?" may be semantically close to the statement "You should always take steps to protect your systems from DDOS attacks", but the statement does not contain the answer to the question. Without reranking, embedding-based retrieval systems often perform well at recall but poorly at precision.
Cross-encoders remedy the limitations of bi-encoders by encoding the query and document together, typically separated by a special token (like [SEP]) using an encoder-only Transformer such as BERT. Then they include an additional fully connected layer that acts as a classifier, learning fine-grained token-level interactions that capture query/document word alignments, answer containment (i.e., does this passage actually answer the question?) and overall contextual relevance.
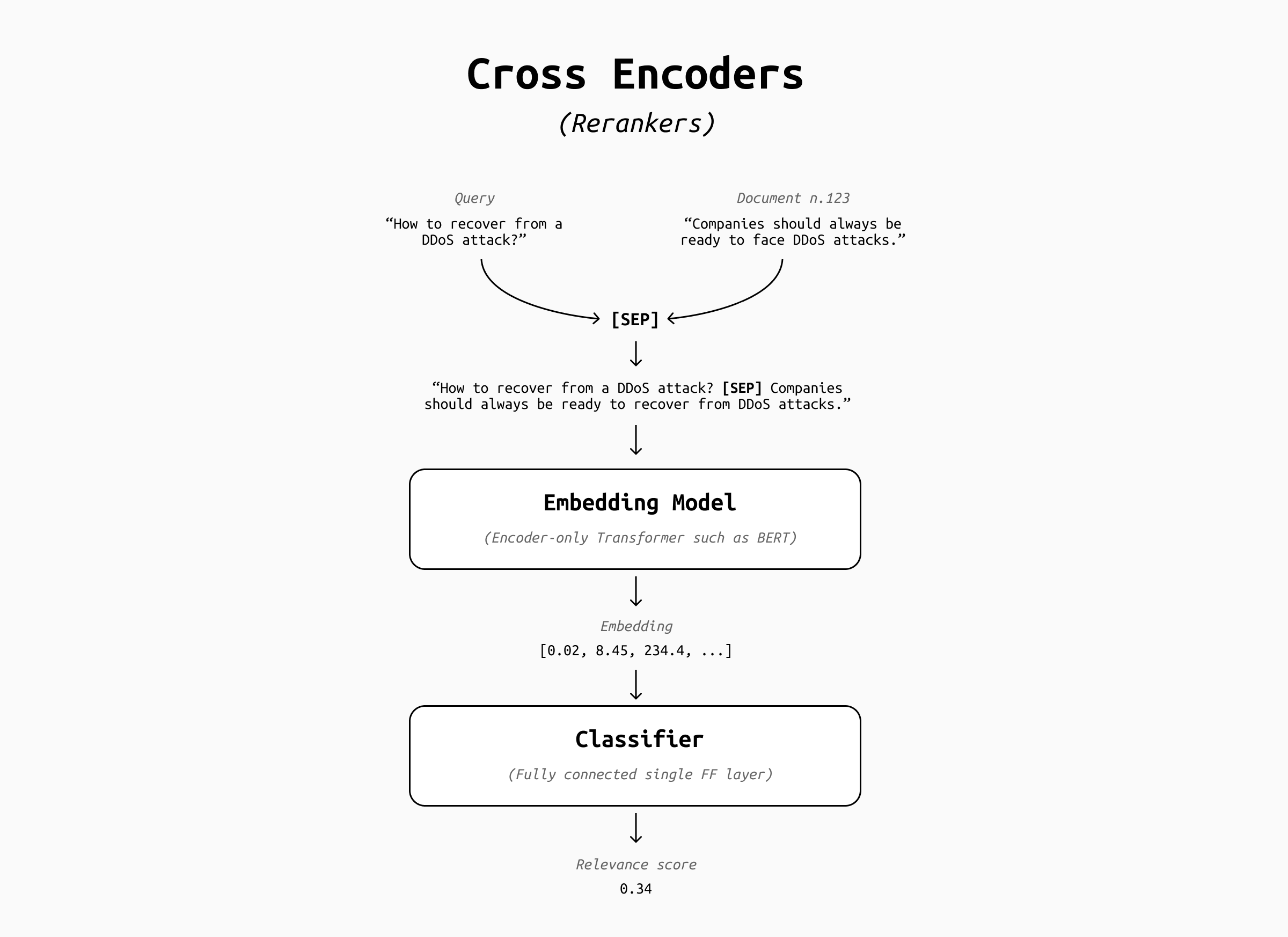
This difference (from separate encodings to a joint representation) gives cross-encoders their power but also their cost. Since relevance depends on the specific query, you can’t precompute the document embeddings: in fact, the concept of "query embedding" and "document embeddings" disappears. Every query-document pair requires a fresh forward pass through the whole model, which can be prohibitively expensive on a large corpus.
To each their place
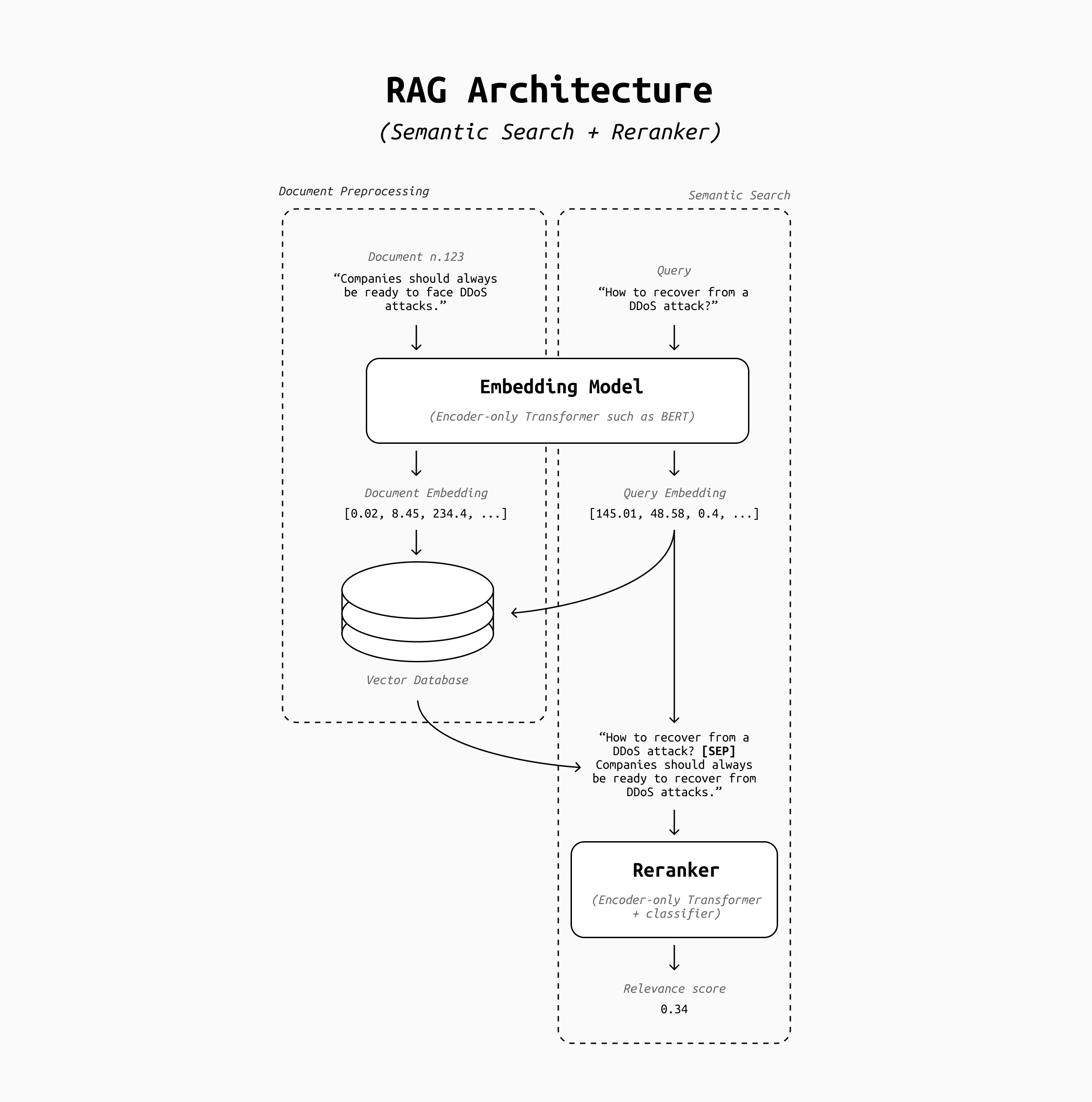
No production system can afford to run interaction-rich models such as cross-encoders on millions of documents per query. Therefore, the two-stage retrieval pipeline remains the industry standard:
-
Semantic Search (Bi-Encoder) – Quickly narrows a massive corpus (e.g., millions of document chunks) down to a small candidate set (e.g., top 100 chunks). Bi-encoders can be built with any embedding model: popular closed source embedders include OpenAI's, Voyage.ai, Cohere's, Gemini and more, while on the open-source front you can find BGE embedders, Mistral's models, Jina.ai, Gemma, IBM Granite, and more.
-
Reranking (Cross-Encoder) – Evaluates those top 100 candidates more deeply by jointly encoding the query and document. A popular closed source choice for reranking models is Cohere's, while on the open source front you can find several Qwen-based rerankers, Jina.ai models, IBM's Granite rerankers, BGE rerankers, and many more.
Making Reranking Practical
Even in this two-tiered system, reranking may turn out to be too expensive for your latency constrains, but several engineering and modeling strategies have emerged to make it viable in production. Let’s break down a few of these methods.
-
Model Distillation
Distillation transfers the knowledge from a large, high-performing cross-encoder (often based on 12-layer BERT or similar) into a smaller student model (e.g., 6 layers, or even lighter). The process involves training the smaller model to mimic the scores or output logits of the larger one on large query–document pairs. While distillation inevitably loses some performance, careful tuning, domain-specific data, and intermediate-layer supervision can retain more than 90% of the original ranking quality at a fraction of the inference cost. You can learn more about model distillation here. -
Listwise Reranking
Instead of scoring each query–document pair independently, listwise reranking generates scores for all top-k candidates in a single forward pass. This approach rearranges candidates into a batched tensor, leveraging GPU parallelism to process them together, reducing overhead from repeated encoder calls. Some implementations also use listwise loss functions (such as ListNet or LambdaMART-inspired objectives) to better preserve ranking order during training. To learn more about ML ranking, have a look at this post. -
Late Interaction Models (e.g., ColBERT)
Late interaction approaches store token-level embeddings of documents from fine-tuned contextual models. At query time, the system encodes the query tokens and performs efficient maximum similarity matching between query tokens and stored document tokens. By avoiding a full joint encoding across all tokens, these models approximate cross-encoder analysis but keep retrieval latency close to bi-encoder speeds. This approach can either substitute or complement cross-encoders by quickly reducing the candidates list returned from the vector database. To learn more about this approach, have a look at this blog post or the ColBERT paper. -
Candidate Filtering and Adaptive k
Rather than always reranking a fixed top-k (like 100 documents), systems can use heuristics or intermediate classifiers to select fewer candidates when confidence in retrieval is high. This adaptive approach can cut reranking costs significantly while preserving precision in challenging cases. -
Approximate Cross-Attention Mechanisms
Instead of computing full self-attention across combined query and document tokens, some approaches reduce complexity by limiting cross-attention depth or dimensionality — for example, attending only to the top N most informative tokens, or pruning low-importance attention heads. This can drastically lower token computations while maintaining critical interaction signals. -
Caching for Frequent Queries
In platforms where certain queries or query patterns repeat, caching reranking results or partial computations can remove the need to rerun the full cross-encoder. Combined with normalization and paraphrase detection, such caches can return precise results instantly for repeated requests.
In production pipelines, these methods are often stacked: for example, using late interaction for most queries, distillation for cost control, and adaptive candidate selection to minimize unnecessary work. The overarching theme is balancing precision and latency, ensuring that rerankers deliver their interaction-driven relevance boost without overwhelming the system’s budget or responsiveness.