What is prompt caching?
Caching prompts can have an outsized impact on the cost and latency of your AI apps. But what exactly to cache and how?
This is episode 2 of a series of shorter blog posts answering questions I received during the course of my work and reflect common misconceptions and doubts about various generative AI technologies. You can find the whole series here: Practical Questions.
A common piece of advice to improve speed and reduce cost of inference in LLMs is to use prompt caching. However, it's often not clear what this means. What exactly is cached? When and why the improvements are really impactful? Understanding prompt caching starts with a deeper awareness of how computation and costs scale with large contexts.
LLMS are stateless
Each time an LLM processes input, it handles every token of the provided context. LLMs are stateless: this means that for every new message added to an existing chat, your application needs to submit the whole history which could include system prompts, documents, examples, and all the chat history.
The model recomputes all of those tokens each time.
This is a massive inefficiency. For example, with an input cost around $1 per 1 million tokens, sending 100,000 tokens across 1,000 requests would cost approximately $100, while about 95% of those tokens remain unchanged across requests. In essence, a large portion of computation is wasted on repeatedly processing information that never changes: the message history.
Stateless vs stateful design
Naive API implementations that omit caching force the model to process the entire context anew each time. This "stateless" method is simpler to implement, but wastefully expensive. The system pays repeatedly to recompute static context, which could otherwise be reused.
In contrast, with a stateful cache strategy, the system stores parts of the context and only processes new inputs (queries). Consider the following case:
- the system prompt is 10,000 tokens long
- each user message is about 100 tokens
- each assistant response is about 1000 tokens
In both cases, the first request processes 10,100 tokens (1 system prompt + 1 user message). On the second message, a stateless request (no caching) needs to process 11,200 tokens (1 system prompt + first user message + first assistant response + the next user message) while a stateful one can first load the cache and then process only 1100 new tokens (the assistant response + the new user message). That's an order of magnitude less tokens!
On top of that, as the chat continues, a stateful app will always need to only process the next new 1100 tokens, while the stateless version will process a chat history that grows by 1100 every time. For example, by the 10th request, with caching you need to process 1100 tokens, while without you need to deal with 20,000! (10,000 system prompt tokens + 9,000 assistant reply tokens + 1000 user message tokens).
Here's a recap to highlight the difference:
| No Prompt Caching | With Prompt Caching | |
|---|---|---|
| 1st request | 10,100 tokens 10,000tk sys + 100tk user |
10,100 tokens 10,000tk sys + 100tk user |
| 2nd request | 11,200 tokens 10,000tk sys + 1000tk llm + (100 * 2) tk user |
1100 tokens 1000tk llm + 100tk user |
| ... | ... | ... |
| 10th request | 20,000 tokens 10,000tk sys + (1000 * 9)tk llm + (100 * 10) tk user |
1100 tokens 1000tk llm + 100tk user |
While cache warm-up is not free, it can make a huge difference in the latency of your responses and, if you're paying by the output token, reduce the costs by orders of magnitude.
Cache Hierarchies
Caching’s benefits come with architectural tradeoffs. Stateless designs are straightforward and predictably expensive: every token is always processed. Caching drastically reduces costs by reusing prior computation, but requires complexity in cache management, such as:
- Cache invalidation: deciding how and when to refresh cached segments.
- Cache misses: when requested information isn’t in the cache, leading to full recomputation and latency spikes.
Because of these challenges, a single monolithic cache usually not enough to see many benefits. The most effective solution is a hierarchical cache strategy.
Effective prompt caching leverages multiple layers with varied lifetimes and hit rates:
- L1: System Prompt (e.g., 5,000 tokens): it rarely changes, so it has the best hit rate. In most chat you'll at least hit this cache.
- L2: System Prompt + Examples and Tools (e.g., +20,000 tokens): may change per task, so it can has a lower hit rate than the system prompt, but eventually it depends completely on your application type. Agentic apps that make heavy use of tools benefit the most from caching them, as they follow the system prompt and might not depend at all from the user query or the agent's decisions.
- L3: System Prompt + Examples and Tools + Documents (e.g., +50,000 tokens): if you're working with documents, caching any initial retrieval can help too. These documents are likely to change per user and/or per session, so it has a moderate/low hit rate. However, the size of these chunks usually makes it worth it if you have some spare capacity or a small and static knowledge base to retrieve from.
A layered approach like balances freshness and reuse, optimizing both cost and performance.
Automatic prefix caching
If you're using a modern inference engine, prompt caching can also be done through automatic prefix caching, where the engine itself takes the responsibility to identify and cache frequently used prefixes. Here you can find more details about the availability of this feature in vLLM, SDLang and llama.cpp, but there are many other engines supporting it.
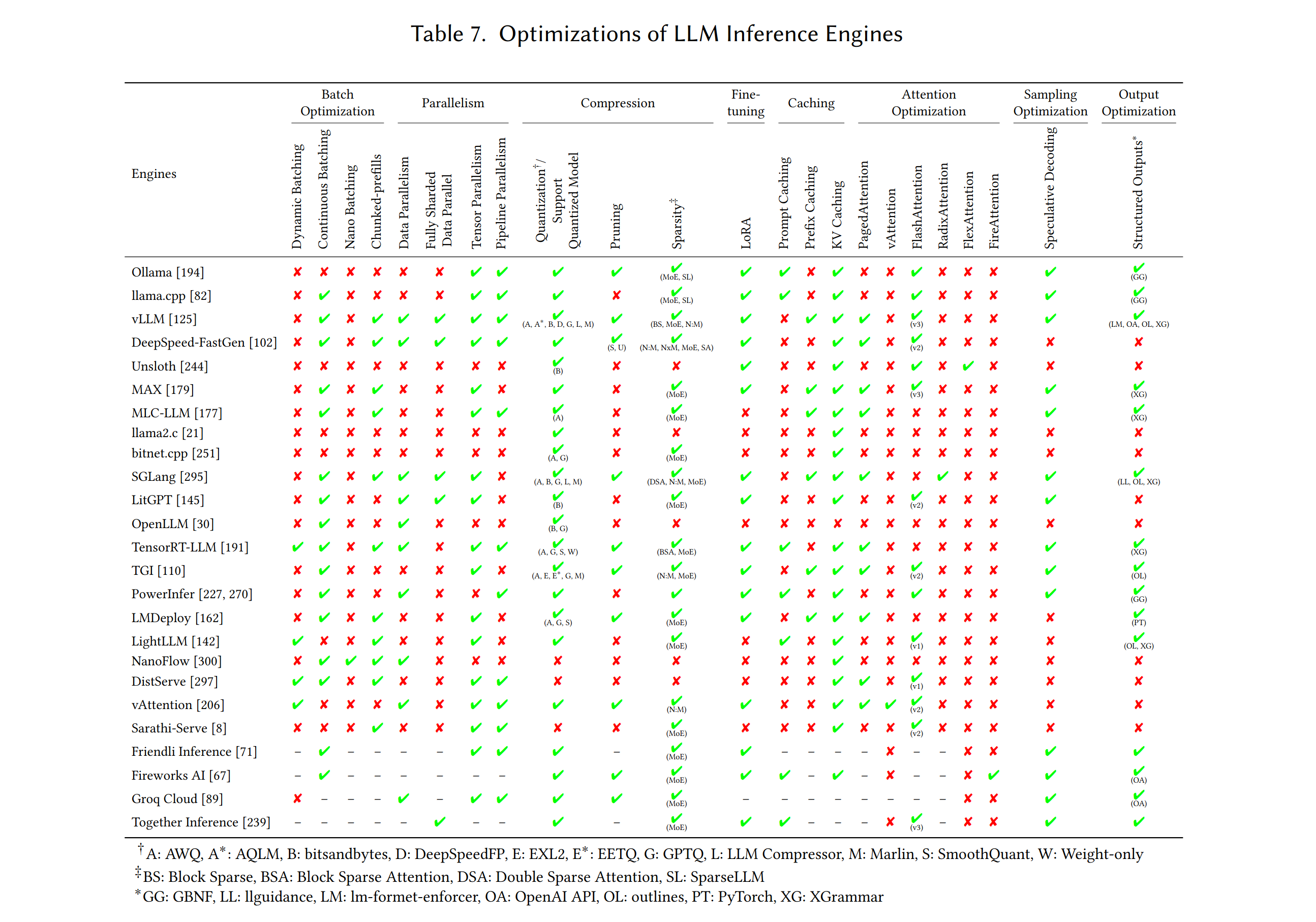
A feature comparison across inference engines from this May 2025 review.
Semantic caching
In extreme cases where cost, load or latency must be reduced to the maximum, semantic caching can also be employed. Semantic caching allows you to cache also the user queries and the assistant responses by keeping a registry of already processes user queries and performing a semantic search step between the new query and the cached ones. If a match is found, instead of invoking the LLM to generate a new answer, the cached reply is sent to the user immediately.
Semantic caching however has several disadvantages that makes it worthwhile only in rare situations:
- Access control. Caching must be done per user if each user has access to a different set of resources, to avoid accidental sharing of data and/or resources across users.
- Very high similarity needed: In order for the reply to be relevant, the semantic similarity between the two must be extremely high, or you risk that the answer returned to the user won't match their question. Semantic similarity tends to overlook details which are often very important to an accurate reply: for example, "What's the sum of these numbers: 1,2,3,4,5,6,7?" and "What's the sum of these numbers: 1,2,3,4,5,6,7,8?" will have an extremely high similarity, but returning the response of the first to the second would not be a good idea.
- Language management: what to do when the exact same question is asked in two different languages? Semantic similarity may be perfect if your embedder is multilingual, but the user won't be pleased to receive a cached answer in a language different from their own.
Such constraints make cache misses extremely frequent, which defies the point of keeping a cache and simply adds complexity and latency to the system instead of reducing it. The similarity pitfalls introduces also nasty accuracy problems.
In my personal experience, semantic caching is only useful for extremely high volume, low cost, public facing interfaces where accuracy is not critical. A perfect example could be a virtual assistant for anonymous customer support, or a helper bot for a software's documentation search. In any case, you usually need additional checks on the output in order to trust such a system.
Conclusion
Prompt caching is not just about cutting costs or speeding things up: it is a necessary architectural approach that addresses the quadratic computational cost inherent in large-context LLM processing. Without it, your backend will repeatedly recompute largely static information, wasting resources and imposing latency penalties that impact your user's experience. By adopting hierarchical, stateful caching and carefully designing prompts, you can reduce token processing costs and response speed by orders of magnitude, which is key for building sustainable, high-performance applications.
In the next post we will talk in detail about how prompt caching works. Be ready for a more technical deep dive into the architecture of LLMs!