Making sense of KV Cache optimizations, Ep. 4: System-level
Let's make sense of the zoo of system-level techniques that exist out there.
In the previous posts we've seen what the KV cache is and what types of KV Cache management optimizations exist according to a recent survey. In this post we are going to focus on system-level KV cache optimizations.
What is a system-level optimization?
Real hardware is not only made of "memory" and "compute", but is made of several different hardware and OS level elements, each with its specific tradeoff between speed, throughput, latency, and so on. Optimizing the KV cache to leverages this differences is the core idea of the optimizazions we're going to see in this post.
Here is an overview of the types of optimizations that exist today.
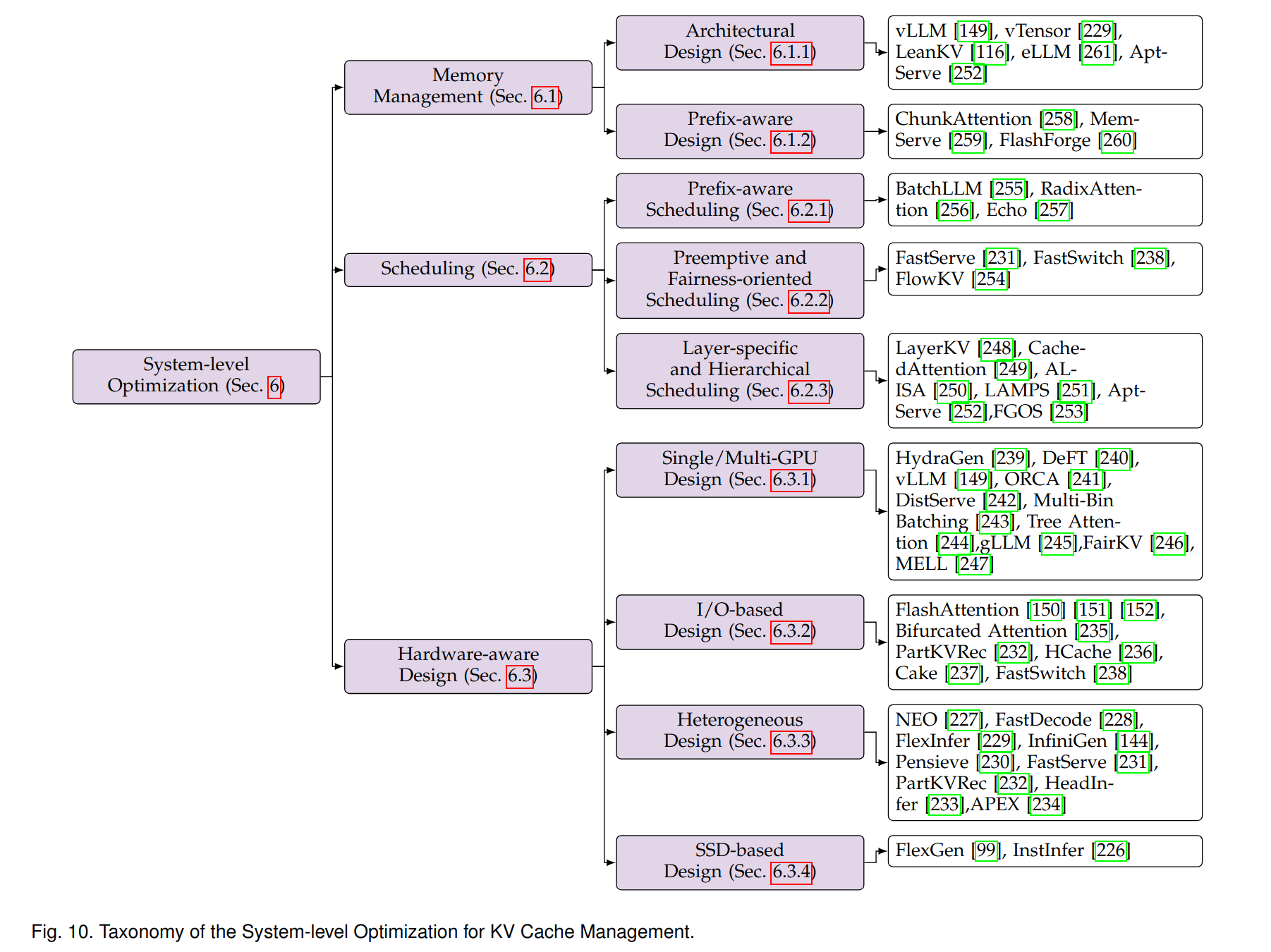
As you can see in the diagram, they can be broadly grouped into three categories: memory management, scheduling strategies, and hardware-aware designs. These approaches are complementary and can be often used together, each addressing different aspects of performance, efficiency, and resource utilization tradeoffs.
Let's see what's the idea behind each of these categories. We won't go into the details of the implementations of each: to learn more about a specific approach follow the links to the relevant sections of the survey, where you can find summaries and references.
Memory Management
Memory management techniques focus on using the different types of memory and storage available to the system in the most efficient way. There are two main approaches to this problem:
- Architectural designs, such as vLLM's PagedAttention and vTensor. These strategies adapt operating system memory management ideas to to create memory allocation systems that optimize the use of physical memory as much as possible. For example, PagedAttention adapts OS-inspired paging concepts by partitioning KV caches into fixed-size blocks with non-contiguous storage, and vLLM implements a virtual memory-like system that manages these blocks through a sophisticated mapping mechanism.
- Prefix-aware designs like ChunkAttention and MemServe. These center around the design of datastructures optimized for maximising cache de-duplication and sharing of common prefixes. For example, ChunkAttention restructures KV cache management by breaking down traditional monolithic KV cache tensors into smaller, manageable chunks organized within a prefix tree structure, enabling efficient runtime detection and sharing of common prefixes across multiple requests.
In general, there's a flurry of novel research focused on the way the KV cache is stored in memory. They bring classic OS memory management patterns and novel designs that leverage the properties of the KV cache at a memory layout level to increase the inference speed and memory consumption issues in a way that's transparent from the model's perspective. This makes these techniques widely applicable to many different LLMs and usually complementary to each other, which multiplies their effectiveness.
For a more detailed description of each technique, check out the survey.
Scheduling
Scheduling techniques focus on maximizing cache hits and minimize cache lifetime by grouping and distributing requests appropriately. In this category we can find a few distinct approaches:
- Prefix-aware scheduling strategies, such as BatchLLM and RadixAttention. For example, unlike traditional LRU caches, BatchLLM identifies global prefixes and coordinates the scheduling of requests sharing common KV cache content. This ensures optimal KV cache reuse while minimizing cache lifetime: requests with identical prefixes are deliberately scheduled together to maximize KV cache sharing efficiency.
- Preemptive and fairness-oriented scheduling, such as FastServe and FastSwitch. For example, FastServe implements a proactive cache management strategy coordinates cache movement between GPU and host memory, overlapping data transmission with computation to minimize latency impact. The scheduler also prioritizes jobs based on input length.
- Layer-specific and hierarchical scheduling approaches, such as LayerKV and CachedAttention. For example, LayerKV focuses on reducing time-to-first-token (TTFT) through a fine-grained, layer-specific KV cache block allocation and management strategy. It also includes an SLO-aware scheduler that optimizes cache allocation decisions based on service level objectives.
For a more detailed description of each technique, check out the survey.
Hardware-aware Design
These techiques focus on leveraging specific characteristics of the hardware in order to accelerate inference and increase efficiency. In this class of optimizazions we can find a few shared ideas:
- Single/Multi-GPU designs focus on optimizing memory access patterns, GPU kernel designs for efficient attention computation, and parallel processing with load balancing. For example, shared prefix optimization approaches like HydraGen and DeFT focus on efficient GPU memory utilization through batched prefix computations and tree-structured attention patterns. Another example is distributed processing frameworks such as vLLM, that optimize multi-GPU scenarios through sophisticated memory management and synchronization mechanisms. Other techniques are phase-aware, like DistServe, which means that they separate prefill and decoding phases across GPU resources to optimize their distinct memory access patterns.
- IO-based designs optimize data movement across memory hierarchies through asynchronous I/O and intelligent prefetching mechanisms.
At the GPU level, approaches like FlashAttention optimize data movement between HBM and SRAM through tiling strategies and split attention computations. At the CPU-GPU boundary, systems like PartKVRec address tackles PCIe bandwidth bottlenecks. - Heterogeneous designs orchestrate computation and memory allocation across CPU-GPU tiers. Systems like NEO or FastDecode reditribute the workload by offloading to the CPU part of the attention computations, while others like FlexInfer introduce virtual memory abstractions.
- SSD-based designs have evolved from basic offloading approaches to more sophisticated designs. For example, FlexGen extends the memory hierarchy across GPU, CPU memory, and disk storage, optimizing high-throughput LLM inference on resource-constrained hardware. InstInfer instead leverages computational storage drives (CSDs) to perform in-storage attention computation, effectively bypassing PCIe bandwidth limitations. These techniques demonstrate how storage devices can be integrated into LLM inference systems either as memory hierarchy extensions or as computational resources.
For a more detailed description of each technique, check out the survey.
Conclusions
System-level KV cache optimizations show that working across the stack can bring impressive speedups and manage physical resources more efficiently than it could ever be done at the LLM's abstraction level. Operating systems and hardware layouts offer plenty of space for optimizations of workloads that have somewhat predictable patterns such as attention computations and KV caching show, and these are just a few examples of what could be done in the near future.
This is the end of our review. The original paper includes an additional section on long-context benchmarks which we're not going to cover, so head to the survey if you're interested in the topic.