DataHour: Optimizing LLMs with Retrieval Augmented Generation and Haystack 2.0
Recording, slides, Colab, gist. All the material can also be found on Analytics Vidhya's community and on my backup.
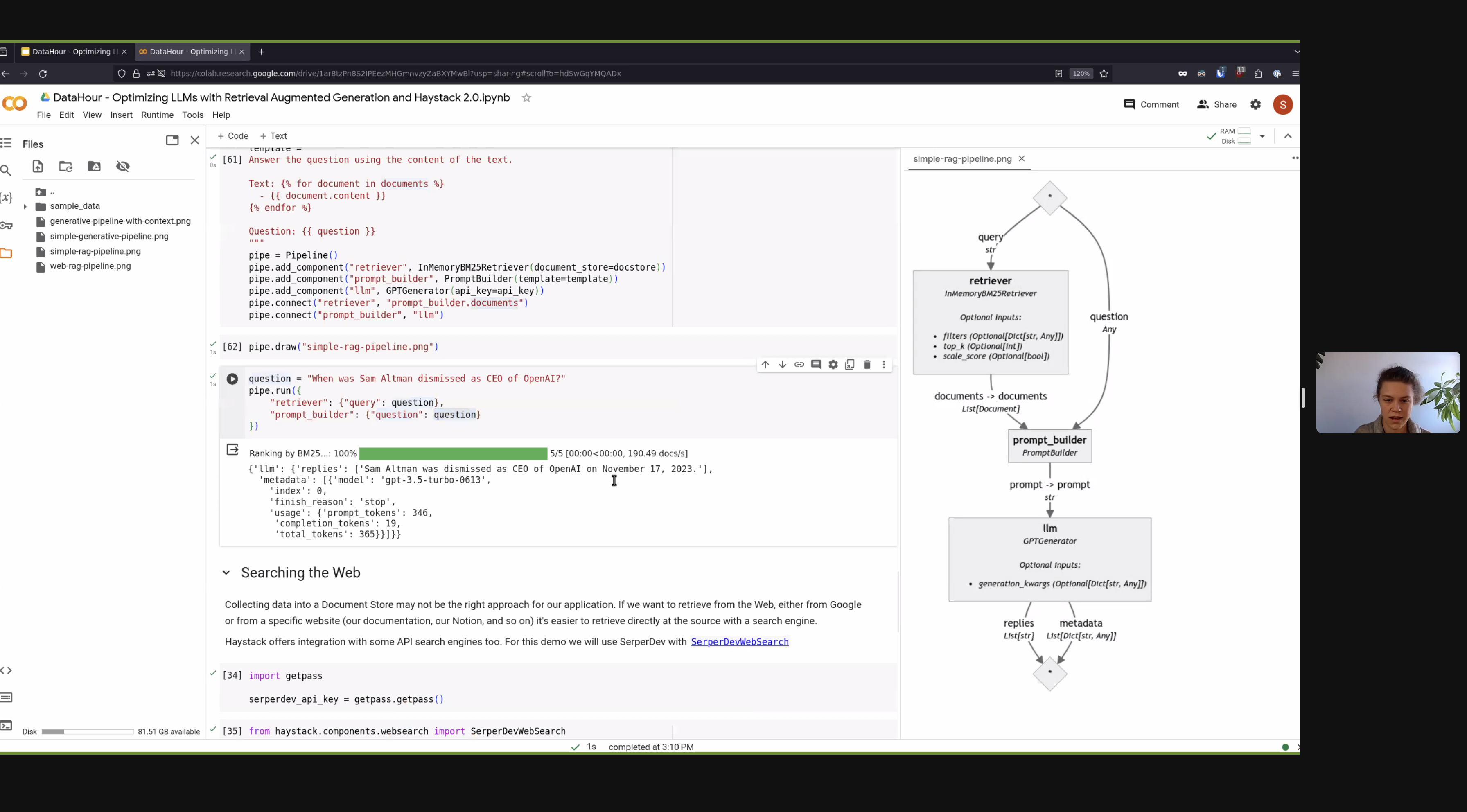
In this hour-long workshop organized by Analytics Vidhya I give an overview of what RAG is, what problems it solves, and how it works.
After a brief introduction to Haystack, I show in practice how to use Haystack 2.0 to assemble a Pipeline that performs RAG on a local database and then on the Web with a simple change.
I also mention how to use and implement custom Haystack components, and share a lot of resources on the topic of RAG and Haystack 2.0.
This was my most popular talk to date, with over a hundred attendees watching live and several questions.
Other resources mentioned in the talk are: