Is RAG all you need? A look at the limits of retrieval augmentation
This blogpost is a teaser for my upcoming talk at ODSC East 2024 in Boston, April 23-25.
Retrieval Augmented Generation (RAG) is by far one of the most popular and effective techniques to bring LLMs to production. Introduced by a Meta paper in 2021, it since took off and evolved to become a field in itself, fueled by the immediate benefits that it provides: lowered risk of hallucinations, access to updated information, and so on. On top of this, RAG is relatively cheap to implement for the benefit it provides, especially when compared to costly techniques like LLM finetuning. This makes it a no-brainer for a lot of usecases, to the point that nowadays every production system that uses LLMs in production seems to be implemented as some form of RAG.
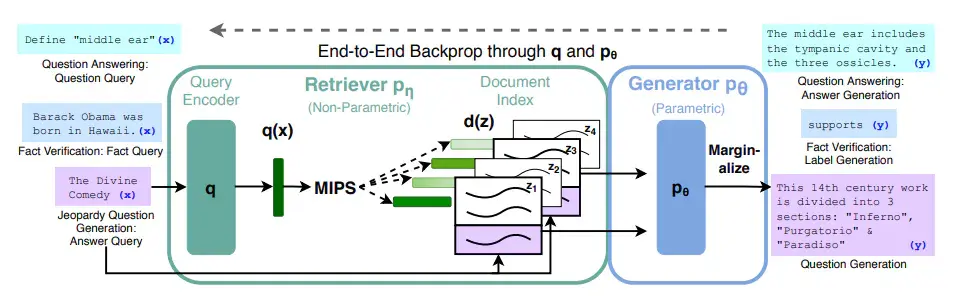
A diagram of a RAG system from the original paper.
However, retrieval augmentation is not a silver bullet that many claim it is. Among all these obvious benefits, RAG brings its own set of weaknesses and limitations, which it’s good to be aware of when scale and accuracy need to be improved further.
How does a RAG application fail?
At a high level, RAG introduces a retrieval step right before the LLM generation. This means that we can classify the failure modes of a RAG system into two main categories:
-
Retrieval failures: when the retriever returns only documents which are irrelevant to the query or misleading, which in turn gives the LLM wrong information to build the final answer from.
-
Generation failures: when the LLM generates a reply that is unrelated or directly contradicts the documents that were retrieved. This is a classic LLM hallucination.
When developing a simple system or a PoC, these sorts of errors tends to have a limited impact on the results as long as you are using the best available tools. Powerful LLMs such as GPT 4 and Mixtral are not at all prone to hallucination when the provided documents are correct and relevant, and specialized systems such as vector databases, combined with specialized embedding models, that can easily achieve high retrieval accuracy, precision and recall on most queries.
However, as the system scales to larger corpora, lower quality documents, or niche and specialized fields, these errors end up amplifying each other and may degrade the overall system performance noticeably. Having a good grasp of the underlying causes of these issues, and an idea of how to minimize them, can make a huge difference.
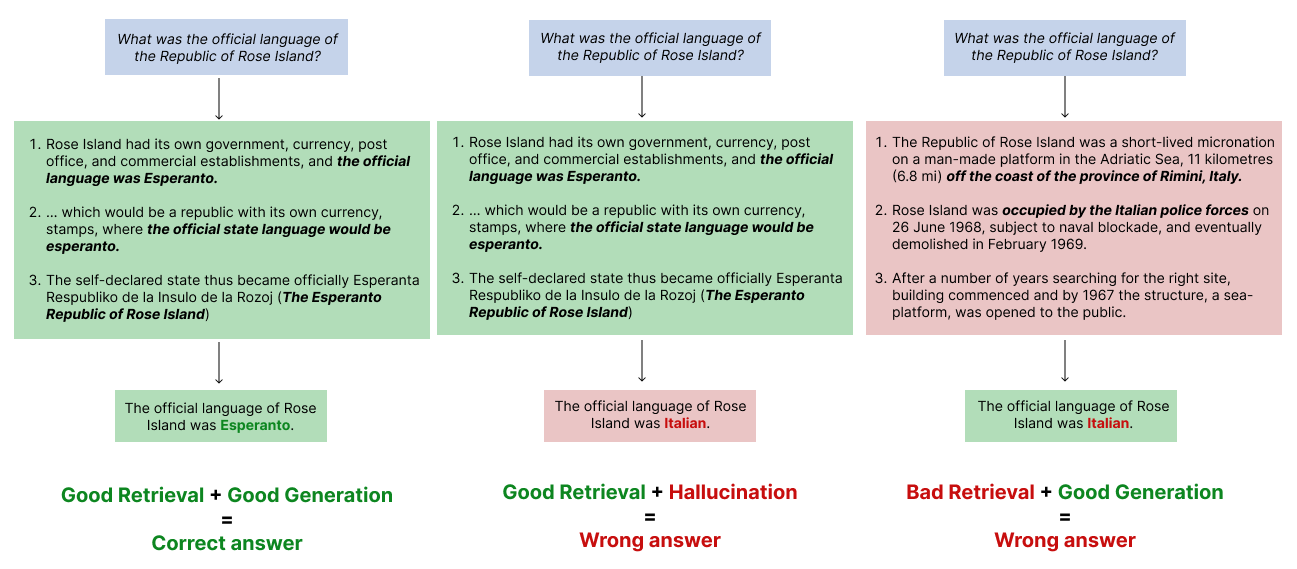
The difference between retrieval and generation failures. Identifying where your RAG system is more likely to fail is key to improve the quality of its answers.
A case study: customer support chatbots
This is one of the most common applications of LLMs is a chatbot that helps users by answering their questions about a product or a service. Apps like this can be used in situations that are more or less sensitive for the user and difficult for the LLM: from simple developer documentation search, customer support for airlines or banks, up to bots that provide legal or medical advice.
These three systems are very similar from a high level perspective: the LLM needs to use snippets retrieved from a a corpus of documents to build a coherent answer for the user. In fact, RAG is a fitting architecture for all of them, so let’s assume that all the three systems are build more or less equally, with a retrieval step followed by a generation one.
Let’s see what are the challenges involved in each of them.
Enhanced search for developer documentation
For this usecase, RAG is usually sufficient to achieve good results. A simple proof of concept may even overshoots expectations.
When present and done well, developer documentation is structured and easy for a chatbot to understand. Retrieval is usually easy and effective, and the LLM can reinterpret the retrieved snippets effectively. On top of that, hallucinations are easy to spot by the user or even by an automated system like a REPL, so they have a limited impact on the perceived quality of the results.
As a bonus, the queries are very likely to always be in English, which happens to be the case for the documentation too and to be the language which LLMs are the strongest at.
The MongoDB documentation provides a chatbot interface which is quite useful.
Customer support bots for airlines and banks
In this case, the small annoyances that are already present above have a much stronger impact.
Even if your airline or bank’s customer support pages are top notch, hallucinations are not as easy to spot, because to make sure that the answers are accurate the user needs to check the sources that the LLM is quoting… which voids the whole point of the generation step. And what if the user cannot read such pages at all? Maybe they speak a minority language, so they can’t read them. Also, LLMs tend to perform worse on languages other than English and hallucinate more often, exacerbating the problem where it’s already more acute.

You are going to need a very good RAG system and a huge disclaimer to avoid this scenario.
Bots that provide legal or medical advice
The third case brings the exact same issues to a whole new level. In these scenarios, vanilla RAG is normally not enough.
Laws and scientific articles are hard to read for the average person, require specialized knowledge to understand, and they need to be read in context: asking the user to check the sources that the LLM is quoting is just not possible. And while retrieval on this type of documents is feasible, its accuracy is not as high as on simple, straightforward text.
Even worse, LLMs often have no reliable background knowledge on these topics, so their reply need to be strongly grounded by relevant documents for the answers to be correct and dependable. While a simple RAG implementation is still better than a vanilla reply from GPT-4, the results can be problematic in entirely different ways.

Research is being done, but the results are not promising yet.
Ok, but what can we do?
Moving your simple PoC to real world use cases without reducing the quality of the response requires a deeper understanding of how the retrieval and the generation work together. You need to be able to measure your system’s performance, to analyze the causes of the failures, and to plan experiments to improve such metrics. Often you will need to complement it with other techniques that can improve its retrieval and generation abilities to reach the quality thresholds that makes such a system useful at all.
In my upcoming talk at ODSC East “RAG, the bad parts (and the good!): building a deeper understanding of this hot LLM paradigm’s weaknesses, strengths, and limitations” we are going to cover all these topics:
-
how to measure the performance of your RAG applications, from simple metrics like F1 to more sophisticated approaches like Semantic Answer Similarity.
-
how to identify if you’re dealing with a retrieval or a generation failure and where to look for a solution: is the problem in your documents content, in their size, in the way you chunk them or embed them? Or is the LLM that is causing the most trouble, maybe due to the way you are prompting it?
-
what techniques can help you raise the quality of the answers, from simple prompt engineering tricks like few-shot prompting, all the way up to finetuning, self-correction loops and entailment checks.
Make sure to attend to the talk to learn more about all these techniques and how to apply them in your projects.