Making sense of KV Cache optimizations, Ep. 1: An overview
Let's make sense of the zoo of techniques that exist out there.
The KV cache is an essential mechanism to avoid the quadratic time complexity of LLM inference and make modern LLMs usable despite huge parameters count and context lengths. However, simply caching everything indiscriminately is not a successful strategy. By swapping time for space complexity, now our problem is GPU memory. Adding more memory can only bring you so far: at some point, you're going to need much more efficient ways to decide what to cache, when and how. But classic cache management techniques were not designed for LLMs, and they often fall short.
With time, a veritable zoo of optimization strategies arose to get around this problem, and making sense of which optimizations can be applied to which model can be a challenge in itself. Fortunately a very comprehensive survey on KV caching recently collected all techniques that make up the state of the art in this field, giving practitioners a handy starting point to understand this field. The amount of techniques reviewed is staggering, so we're going to need more than one post to go through the most interesting approaches and compare them.
For now, let's see how we can start to make sense of things.
The challenges
Most of the techniques we're going to see address one or more of these issues.
- Cache Eviction: Determining which items to evict when the cache reaches its capacity. Popular policies like Least Recently Used (LRU) or Least Frequently Used (LFU) do not always align with LLM usage patterns, leading to suboptimal performance.
- Memory Management: The memory required for the KV cache grows linearly with both the input length and the number of layers, which can quickly exceed the hardware memory limits. It's possible to overcome such limits by distributing the storage of this cache across different types of storage hardware (e.g., GPU, CPU or external memory), but this brings its own set of challenges.
- Latency: Accessing and updating the cache at each decoding step can introduce latency.
- Compression: Compressing the KV cache can reduce memory usage but may degrade model performance if key information is lost.
- Dynamic Workloads: Handling dynamic and unpredictable workloads, where access patterns and data requirements frequently change, requires adaptive caching strategies that can respond in real time.
- Distributed Coordination: In distributed KV caches, maintaining coordination across multiple nodes to ensure consistency, fault tolerance, and efficient resource usage adds significant complexity.
A taxonomy
In order to make sense of the vast amount of known techniques, the authors categorized them into a comprehensive taxonomy.
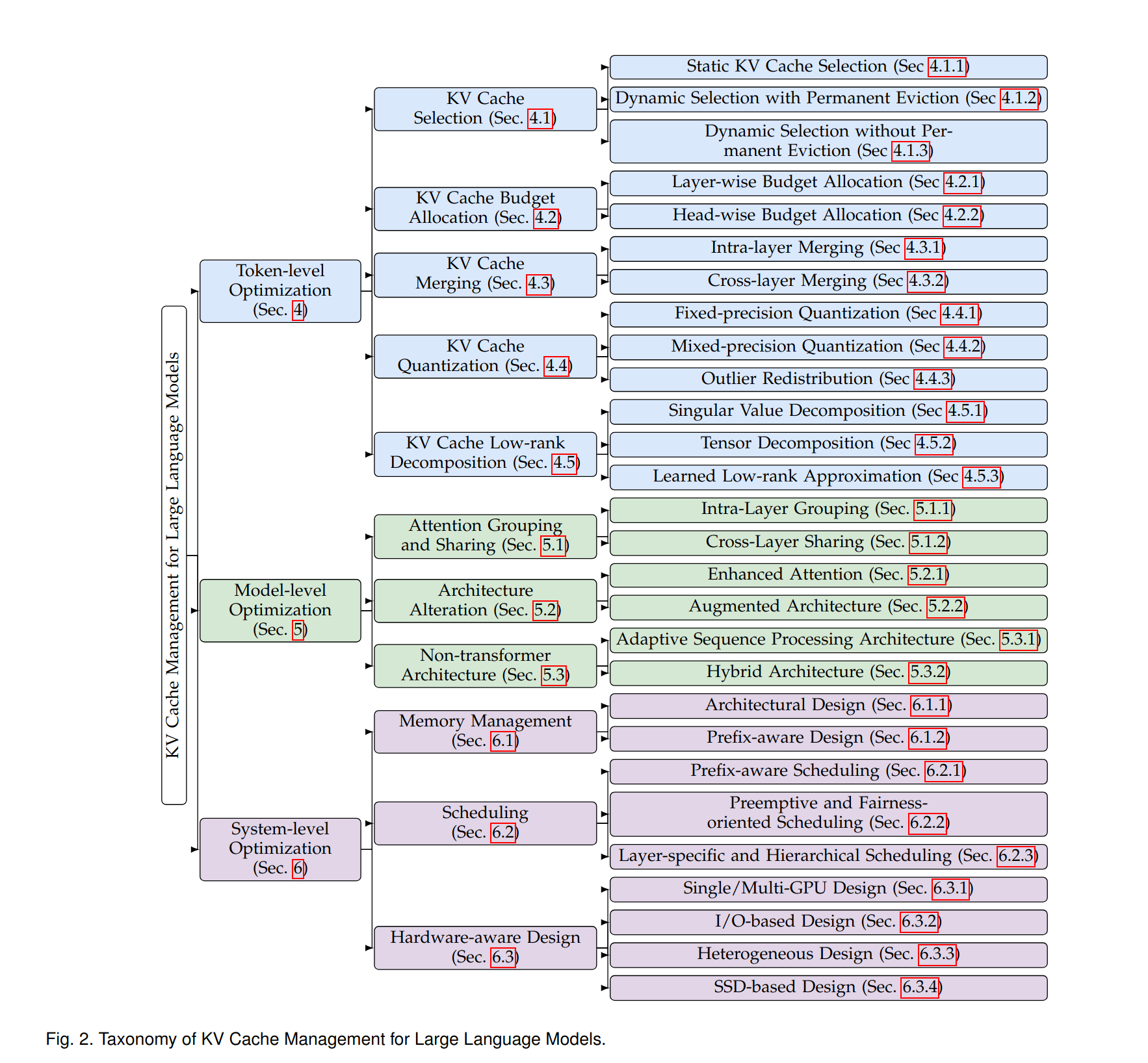
It starts with three major categories:
- Token-Level Optimization: improving KV cache management efficiency by focusing on the fine-grained selection, organization, and compression at the token level. These techniques can be applied to any model, as they require no architectural changes.
- Model-level Optimization: designing an efficient model structure to optimize KV cache management. These optimizations are strictly model-dependent, because they're backed into the model's architecture.
- System-level Optimization: optimizing the KV Cache management through techniques closer to the OS and/or the hardware. These techniques may require specialized hardware to implement, so they're not at everyone's reach.
Token-Level Optimizations
Token-level optimizations are the most readily accessible to most developers, as they require no dedicated support from the LLM and no specialized hardware. Therefore, these are usually the most interesting. In this category we find:
- KV cache selection: focuses on prioritizing and storing only the most relevant tokens.
- KV cache budget allocation: dynamically distributes memory resources across tokens to ensure efficient cache utilization under limited memory.
- KV cache merging: reduces redundancy by combining similar or overlapping KV pairs.
- KV cache quantization: minimizes the memory footprint by reducing the precision of cached KV pairs.
- KV cache low-rank decomposition: uses low-rank decomposition techniques to reduce cache size.
Model-Level Optimizations
Model-level optimizations, as the name says, are baked into the model's architecture and therefore are either not applicable or always present in the models you're running. These optimizations are usually interesting for people that design their own model architecture and train them, rather than developers that work with off-the-shelf models. In this category we find:
- Attention grouping and sharing methods: examine the redundant functionality of keys and values and group and share KV cache within or across transformer layers.
- Architecture alterations: emerge to design new attention mechanisms or construct extrinsic modules for KV optimization.
- Non-transformer architectures: architectures that adopt other memory-efficient designs like recurrent neural networks to optimize the KV cache in traditional transformers.
System-level Optimizations
These optimizations work across the stack to provide the best possible support to the LLM's inference, and they're sometimes baked into the inference engine, such as vLLM's PagedAttention. They occasionally require dedicated hardware and OS optimizations, so they're not always readily available for everyday experimentation. They include:
- Memory management: focuses on architectural innovations like virtual memory adaptation, intelligent prefix sharing, and layer-aware resource allocation.
- Scheduling: addresses diverse optimization goals through prefix-aware methods for maximizing cache reuse, preemptive techniques for fair context switching, and layer-specific mechanisms for fine-grained cache control.
- Hardware acceleration: including single/multi-GPU, I/O-based solutions, heterogeneous computing and SSD-based solutions.
Conclusion
KV cache optimization is still an open research area, with new techniques and improvements being published regularly. A good overview of what types of optimizations exist can help you make sense of the zoo of acronyms and claims being made about them, and give you the foundations you need to understand if a particular technique is relevant for your situation. Stay tuned for the next posts, where we will dive deeper into each of these categories.