Making sense of KV Cache optimizations, Ep. 3: Model-level
Let's make sense of the zoo of model-level techniques that exist out there.
In the previous posts we've seen what the KV cache is and what types of KV Cache management optimizations exist according to a recent survey. In this post we are going to focus on model-level KV cache optimizations.
What is a model-level optimization?
We call a model-level optimization any modification of the architecture of the LLM that enables a more efficient reuse of the KV cache. In most cases, to apply these method to an LLM you need to either retrain or at least finetune the model, so it's not easy to apply and is usually baked in advance in of-the-shelf models.
Here is an overview of the types of optimizations that exist today.
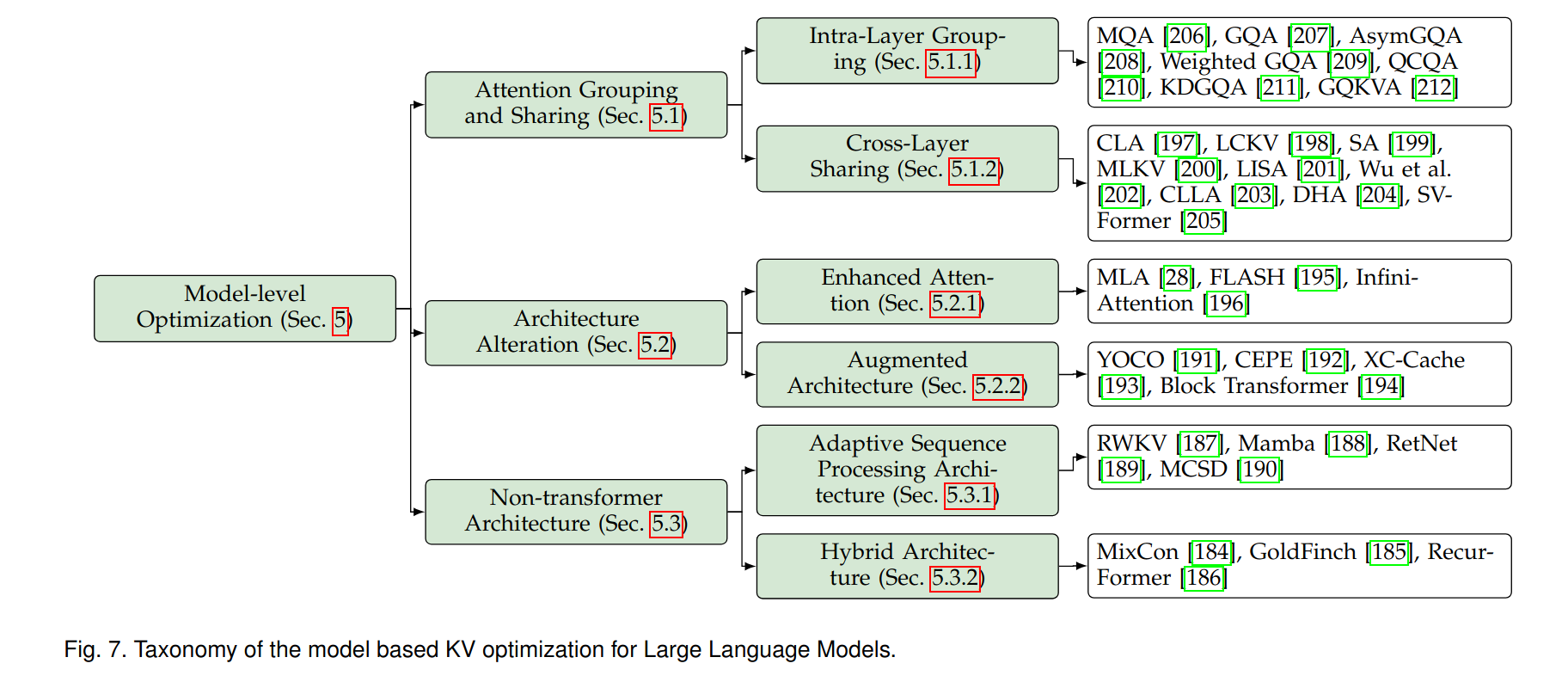
Let's see what's the idea behind each of these categories. We won't go into the details of the implementations of each: to learn more about a specific approach follow the links to the relevant sections of the survey, where you can find summaries and references.
Attention Grouping and Sharing
One common technique to reduce the size of the KV cache is to group and/or share attention on different levels. There's techniques being developed for different grades of attention grouping:
- Intra-layer grouping: focuses on grouping query, key, and value heads within individual layers
- Cross-layer sharing: shares key, value, or attention components across layers
At the intra-layer level, the standard architecture of Transformers calls for full multi-headed attention (MHA). As an alternative, it was proposed to have all attention heads share a single key and value, reducing dramatically the amount of compute and space needed. This technique, called multi-query attention (MQA) is a radical strategy that would cause not just quality degradation, but also training instability. As a compromise, grouped-query attention (GQA) was proposed by dividing the query heads into multiple groups, while each group shares its own keys and values. In addition, an uptraining process has been proposed to efficiently convert existing MHA models to GQA configurations by mean-pooling the key and value heads associated with each group. Empirical evaluations demonstrated that GQA models achieve performance close to the original MHA models.
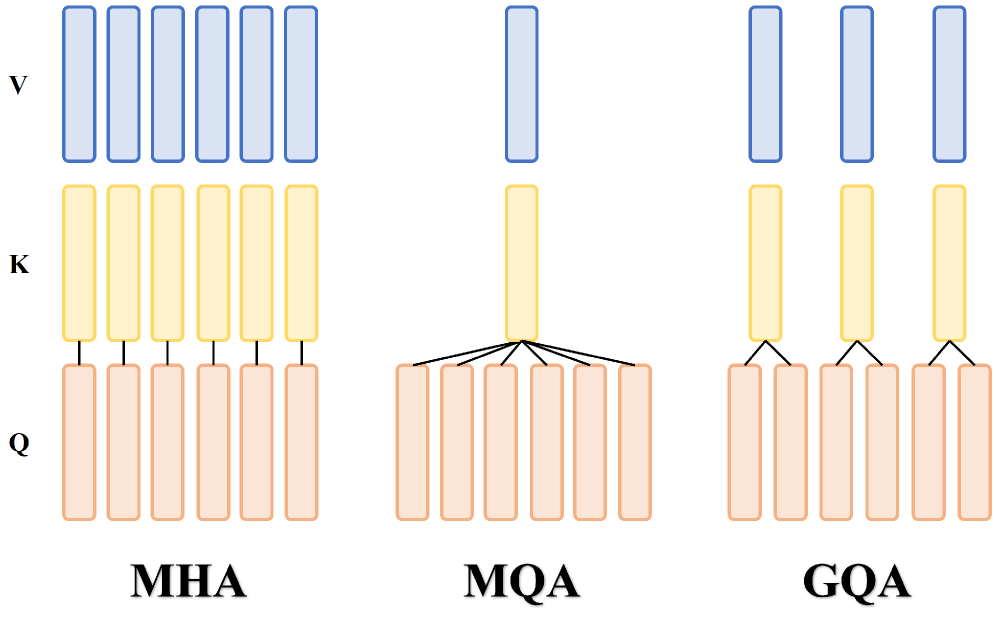
A simplified illustration of different QKV grouping techniques: multi-headed attention (MHA), multi-query attention (MQA) and grouped-query attention (GQA).
Across layers, cross-layer attention (CLA) was proposed to extends the idea of GQA. Its core idea is to share the key and value heads between adjacent layers. This achieves an additional 2× KV cache size reduction compared to MQA. Several other approaches exist to address cross-layer attention sharing, so check out the survey if you want to learn more.
In general, the main issue in this line of research regards the model modifications that needs to be applied. Current approaches often fail to generalize well to architecture they were not initially designed on, while more static and general grouping/sharing strategies fail to capture important variations in the various heads and layers, leading to a loss of output quality. In addition, the need to retrain the LLM after the changes limits strongly the portability of these methods.
For a more detailed description of each technique, check out the survey.
Architecture Alteration
Another approach is to make more high-level architectural changes to reduce the required cache size. There seems to be two main directions in this area:
- Enhanced Attention: methods that refine the attention mechanism for KV cache efficiency. An example is DeepSeek-V2, which introduced Multi-Head Latent Attention (MLA). This technique adopts a low-rank KV joint compression mechanism and replaces the full KV cache with compressed latent vectors. The model adopts trainable projection and expansion matrices to do the compression. This compression mechanism is what enables the model to handle sequences of up to 128K tokens. You can learn more about MLA in this article by Sebastian Raschka.
- Augmented Architecture: methods that introduce structural changes for better KV management, for example novel decoder structures (such as YOCO, that included a self-decoder and a cross-decoder step).
Many of these works build upon the broader landscape of efficient attention mechanisms (e.g., Linear Transformer, Performer, LinFormer, etc.) which already have their own survey.
Although these approaches demonstrate significant progress in enabling longer context windows and faster inference, there are still big challenged ans unknowns. Some techniques in this category, for example, perform very well for some tasks but fail to generalize (for example they work well with RAG but not with non-RAG scenarios).
For a more detailed description of each technique, check out the survey.
Non-Transformer Architecture
In this category we group all radical approaches that ditch the Transformers architecture partially or entirely and embrace alternative models, for example RNNs, which don't have quadratic computation bottlenecks at all and sidestep the problem entirely.
In the case of completely independent architectures, notable examples are:
- Mamba, based on state space sequence models (SSMs). Mamba improves SSMs by making parameters input-dependent, allowing information to be selectively propagated or forgotten along the sequence based on the current token. Mamba omits attention entirely.
- RWKV (Receptance Weighted Key Value) integrates a linear attention mechanism, enabling parallelizable training like transformers while retaining the efficient inference characteristics of RNNs.
Efficient non-Transformers also have their own surveys, so check out the paper to learn more.
For a more detailed description of each technique, check out the survey.
Conclusion
Model-level optimizations go from very light touches to the original Transformer model to architecture that have nothing to do with it, therefore not having any KV cache to deal with in the first place. In nearly all cases the principal barrier to adoption is the same: applying these techniques requires a full retraining of the model, which can be impractical at best and prohibitively expensive at worst, even for users that have the right data and computing power. Model-level optimizations are mostly useful for LLM developers to get an intuition of the memory efficiency that can be expected from a model that includes one or more of these features out of the box.
In the next post we're going to address system-level optimizations. Stay tuned!