What's hybrid retrieval good for?
We've been told embedding search strictly superior to BM25 and all other keyword-search algorithms. But they still have a role in modern search pipelines.
This is episode 4 of a series of shorter blog posts answering questions I received during the course of my work. They discuss common misconceptions and doubts about various generative AI technologies. You can find the whole series here: Practical Questions.
It has been a long time since TF-IDF or even BM25 were the state of the art for information retrieval. These days the baseline has moved to embedding similarity search, where each unit of information, be it a sentence, a paragraph or a page is first encoded in an embedding and then compared with the embedding of the user's query.
From this baseline there are often two pieces of advice to help you increase the performance of your search system: one is to go the deep end with the embedding approach and consider a reranker, finetune your embedding model, and so on. The other, usually called hybrid retrieval or hybrid search, is to bring back good old keyword search algorithms and use them to complement your results. Often the best scenario is to use both of these enhancements, which nicely complement each other.
But why would this arrangement help improve the results? Isn't embedding search strictly superior to keyword-based retrieval algorithms?
Semantic vs Lexical
When you embed a sentence, the resulting embedding encodes its meaning, not its exact phrasing. That’s their strength! But it can often be a limitation as well.
For example a semantic model can understand that "latest iPhone" is similar to "iPhone 17 Pro Max", which is great if the first sentence is a query and the second the search result. But a semantic model will also say that "iPhone 17 Pro Max" and "iPhone 11 Pro Max" are very similar, which is not great if the first sentence is a query and the second a search result.
In short, semantic similarity is great if you are starting from a generic query and you want a set precise result all matching the generic description, or if you start from a general question and want to retrieve all very particular results that fall under the same general concept. For "latest iPhone", "iPhone 17 Pro Max", "iPhone 17 Pro" and ideally "iPhone Air" and are all valid search results.
On the other hand, lexical similarity is what allows your system to retrieve extremely precise results in response to a very specific query. "latest iPhone" will return garbage results with a lexical algorithm such as BM25 (essentially any iPhone would match), but if the search string is "iPhone 17 Plus Max", BM25 will return the best results.
To visualize it better, here's the expected results for each of the two queries in a dataset of iPhone names:
| User Query | Semantic Search Results | Keyword Search Results |
|---|---|---|
| "latest iPhone" |
|
|
| "iPhone 17 Pro Max" |
|
|
As you can see, the problem is that neither of the two approaches works best with both types of queries: each has its strong pros and cons and works best only on a subset of the questions your system may receive.
So why not using them both?
Combining them
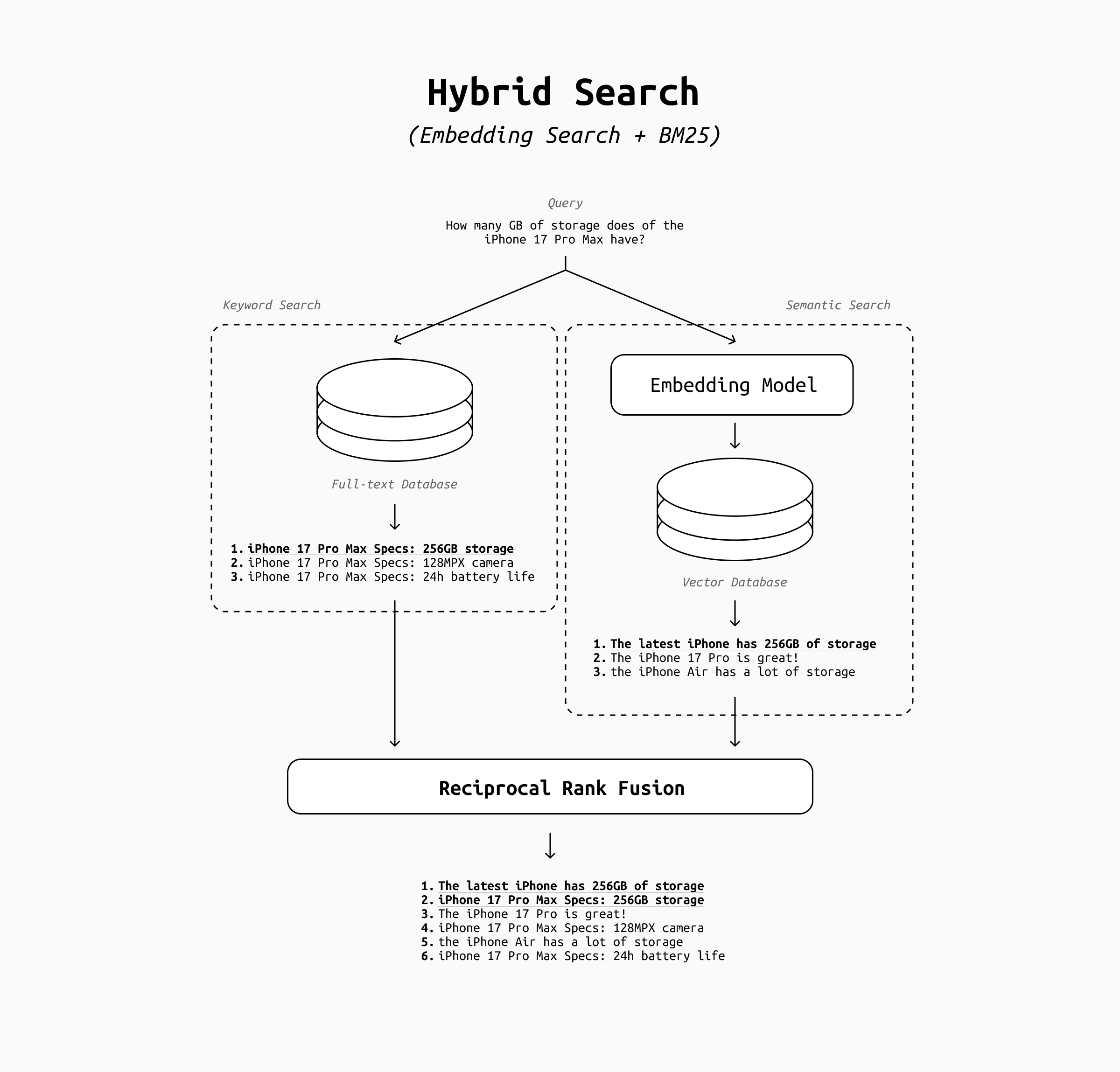
A hybrid search system is simply a system that does the same search twice: once with a keyword algorithm such as BM25, and once with vector search. But how to merge the two lists of results?
The scores the documents come with are deeply incomparable. BM25 scores depends on terms frequency and keyword matching, and are not bound to any range. On the contrary, cosine similarity usually clusters between 0.5 and 0.9, which gets even narrower if the sequences are longer.
That's where reciprocal rank fusion (RRF) comes in. RRF is incredibly simple and boils down to this formula: score(d) = sum( 1/(k + rank_method_i(d)) ) . As you can see it works on the ranks, not scores, so it’s robust against scale differences and requires no normalization. Platforms like Elastic and Pinecone use it for production hybrid search due to its simplicity and reliability. Being so simple, the additional latency is negligible, which makes it suitable for real-time usecases.
Or, if you're less concerned about latency, you can consider adding a reranker.
Having two independent and complementary search techniques is the reason why adding a reranker to your hybrid pipeline is so effective. By using these two wildly different methods, it's not obvious whether even the rankings are comparable. Rerankers can have a more careful look at the retrieved documents and make sure the most relevant documents are to the top of the pile, allowing you to cut away the least relevant ones.
Conclusion
Hybrid search isn’t a patch for outdated systems, but a default strategy for any high-quality retrieval engine. Dense embeddings bring rich contextual understanding, while sparse retrieval ensures accuracy for unique identifiers, numeric codes, acronyms, or exact strings that embeddings gloss over. In a world where search systems must serve both humans and machine agents, hybrid search is the recall multiplier that guarantees we get both meaning and precision.